

On 14th of March, our group attended an AI for Good webinar organized by the International Atomic Energy Agency (IAEA) entitled “AI for advancing fusion energy through enhancing simulation”. The talk was delivered by Dr. Michael Churchill from the Princeton’s Plasma Physics Laboratory. The main scope of the webinar was focused on the role of artificial intelligence (AI) in advancing sustainable development goals, specifically towards fusion energy as well as the potential of AI in enhancing simulation and accelerating research and development (R&D) in nuclear fusion.
In recent years, fusion energy has been receiving renewed attention from private companies that have shown a keen interest in investing in this technology. Along with the construction of the ITER magnetic confinement fusion device, breakthroughs in this field have presented many opportunities to leverage machine learning (ML) to enhance simulations and optimize the performance of these devices. Despite the long history of research and development associated with fusion energy, the recent advancements in this field have sparked renewed excitement and promise for the future.
In the first half of the webinar, Dr. Churchill talked about the implementation of ML in fusion codes in order to speed up fusion simulations. More concretely, they presented the X-Point Included Gyrokinetic Code (XGC), a large-scale gyrokinetic code, in simulating turbulence and transport in the tokamak edge. The tokamak edge is critical for predicting the heat loads to the wall, preventing wall melting, and achieving high-performing edge regions that lead to higher core performance and ultimately the desired fusion energy output. XGC code simulates the entire particle distribution function in three-dimensional space and two-dimensional velocity, making it massively parallel and requiring extremely large supercomputers to run.

One of the challenges with XGC code is the collisions between particles, which is solved using the Fokker-Planck collision operator. “This collision operator scales quadratically with the number of species and can become a bottleneck for XGC simulations involving multiple charge state impurities. To allow for more detailed simulations, including many impurities, the collision operator needs to be accelerated”, remarked Dr. Chruchill.
The basic algorithm for XGC code involves using the Boltzmann equation to derive equations of motion for particles. XGC uses a particle-in-cell method that samples particles, moves them according to the equations of motion, and deposits them onto spatial grids in 2D velocity space. Collisions and other sources are solved on this 2D Eulerian grid, where each spatial point is independent, and the collision operator is run on each 2D grid. In addition, the traditional solver in XGC is implicit and uses backward Euler and Picard iteration for fixed-point iteration, with a convergence criteria of the change in density, momentum, and energy being below a threshold. XGC is a particle-in-cell code, meaning there is inherent noise in the process due to Monte Carlo methods. In particular, says Dr. Churchill, “this noise is relevant in how we think about entrained neural networks“.
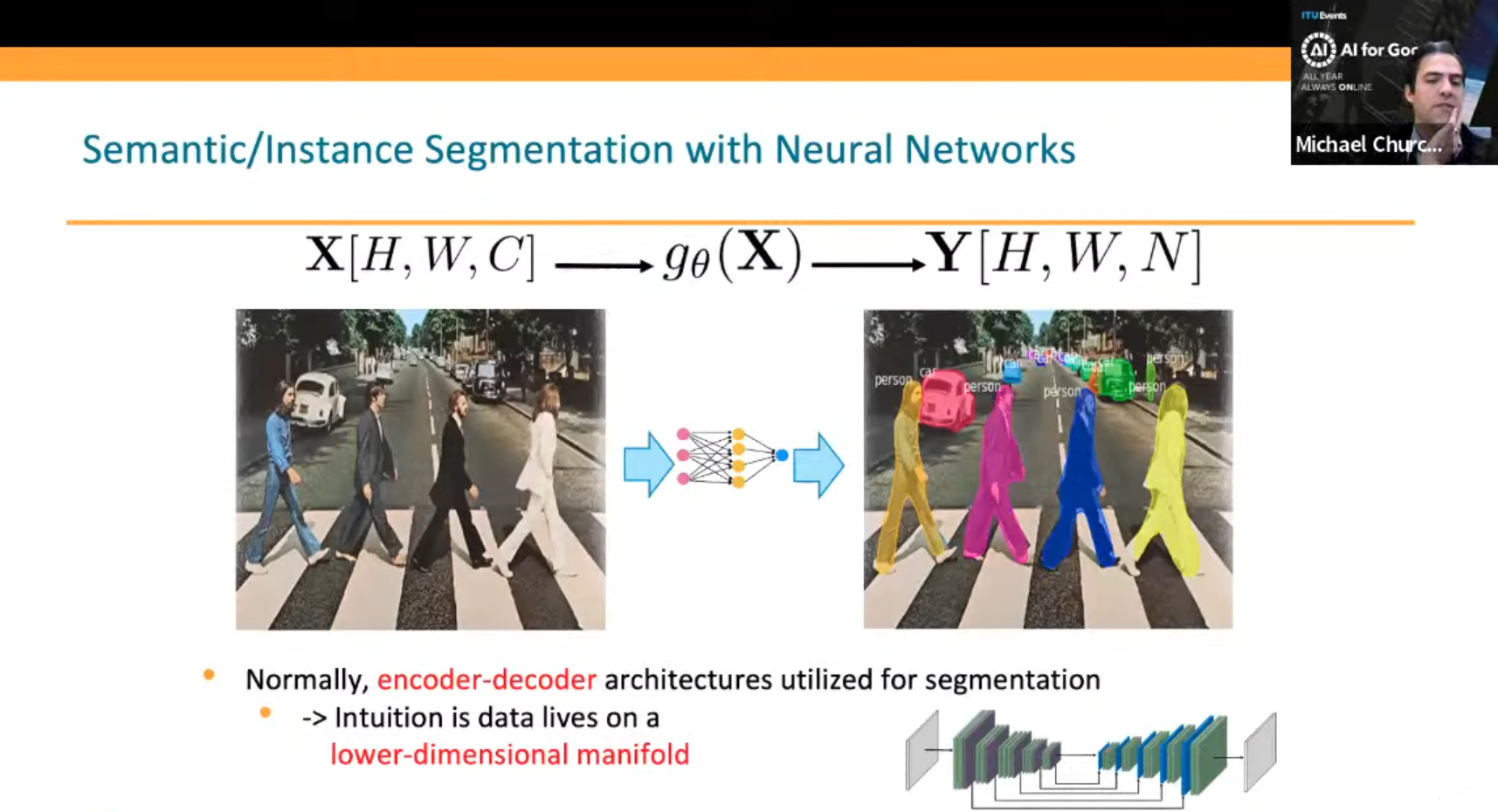
The speaker presented the Reseg architecture, a neural network for image segmentation, that was used for a particular case involving XGC data. The Reseg architecture was chosen because allowed the neural network to extract local and global features. The initial results were promising, with the loss decreasing significantly in ion momentum and energy. Moreover, the Stochastic Augmented Lagrangian algorithm was used to modify the lambda parameters, which increased as the constraints became smaller, ensuring that conservation constraints were primarily important. Applying the Reseg architecture to XGC was accomplished using TorchScript inside the PyTorch API, which allowed the model to be called inside C++ for inference. The results showed that the machine learning collision operator was 54x faster than the CPU-only version and about 4.5x to 5x faster than a more optimized traditional solver using GPUs. However, the machine learning collision operator caused an avalanching increase in density after some time, which required adjustments.
The second half of the webinar was devoted to the use of machine learning for simulation and experimental data comparison. “The motivation for this work was to use reduced models, which can be run more often but require ad hoc simulation inputs because they do not capture all the high fidelity physics”, highlighted Dr. Churchill. These inputs are usually tuned by hand to match the simulation with experiment, but it is not clear what the range of validity of these ad hoc inputs is. Traditional methods such as Markov Chain Monte Carlo (MCMC) are often used for statistical inference, but they are sequential and can require hours, making it difficult to scale to the number of experimental points in fusion experiments.
The speaker presented recent work in simulation-based inference (SBI) or likelihood-free inference, which uses neural networks to enable Bayesian inference. The setup involved a model or simulator, a prior over the parameters, and experimental data. The neural network then took the input parameters and the forward model generating the observables and learned to do the inference process, resulting in a posterior that showed consistent or inconsistent samples with the experimental data. The speaker also discussed neural posterior estimation and sequential neural posterior estimation and their pros and cons.
As future work, Dr. Churchill said that they plan to include experimental noise in their SBI workflow, which they are currently applying to a real fusion diagnostic. They believe this approach will allow for quick extraction of measurements with uncertainties and be extensible to include further diagnostics. They also plan to create amortized models with a large number of simulations that could be routinely applied to experimental output, which will improve understanding of how well simulation models match experimental data.
In the last part of the webinar, Dr. Churchill concluded that machine learning has great potential in accelerating simulation and connecting it with fusion energy experiments. They demonstrated an encoder-decoder neural network that replicated the nonlinear Fokker-Planck collision operator and sped up simulations by 5x. They also presented SBI inference workflows that enable fast inference of physical quantities from experiment with uncertainties on ad hoc parameters and simulations. The speaker emphasizes the importance of custom data normalization and training constraints and highlights the benefits of these workflows in understanding where simulator physics models break down as well as in reducing the number of simulation runs needed for a result.
The webinar ended up with a Q&A session where Dr. Churchill discussed various neural network architectures and their trade-offs, particularly in the context of plasma physics. They also talked about SBI workflows and their benefits for adapting to new machines. In addition, the speaker addressed some technical questions related to deep learning models, such as the causes of artifacts near image edges and the potential for using faster models for simulations. Lastly, the speaker gave their thoughts on DeepMind‘s work on fusion plasma control, which they described as a good proof of principle.
For more details, please see the recording of the webinar on AI for Good’s YouTube channel.